3가지 타입의 머신 러닝
- yhs901201
- 2023년 1월 15일
- 2분 분량
최종 수정일: 2023년 1월 16일
지도 학습 (Supervised learning)
비지도 학습 (Unsupervised learning)
강화 학습 (Reinforced learning)
문헌에 따라 지도학습과 비지도학습의 중간개념으로 준(반)지도학습 (Semi-supervised learning) 또는 약지도학습 (Weakly supervised learning)이 있다.
주어진 데이터의 라벨링이 항상 다 되어 있지 않을수도 있고 라벨의 비율이 현저히 차이가 날때는 지도학습 대신 준지도학습을 이용한다.
지도 학습 (Supervised learning)
지도 학습은 머신 러닝 알고리즘을 학습시키기 위해 학습 데이터가 주어졌을 때, 그에 대한 정답도 같이 주어지는 것을 의미한다. 이렇게 학습된 알고리즘은 예측 모델에 주어지고 예측해야 하는 데이터가 정답이 없이 주어지면 정답을 맞추는 흐름을 뜻한다.
지도 학습은 크게 두가지 문제로 나뉜다:
분류 (classifcation) 문제
회귀 (regression) 문제
분류 (classifcation)
분류 문제는 카테고리 데이터를 학습할 때 용이하다.
예를 들어 스팸 메일을 걸러내야 하는 문제가 주어졌다고 가정할 때, 우리는 스팸 또는 스팸이 아닌 메일들을 학습한 모델을 통해 새로운 메일이 왔을 때 해당 메일이 스팸인지 아닌지를 구분하게 된다.
이렇게 라벨 값을 맞추는 문제를 우리는 분류 (classification) 문제라고 부른다.
위 예시처럼 모델이 예측값을 두가지로 분류 해야 하는 방식을 이진 분류 (binary classification) 이라고 부르고, 여러개로 분류해야 하는 방식을 다중 분류 (multiclass classification) 이라고 부른다.
알파벳 대문자 손글씨 (A-Z)를 분류하는 문제를 다중 분류 문제로 들수가 있다.
회귀 (regression)
지도 학습의 다른 하위 카테고리는 회귀 문제가 있다.
연속적인 데이터가 주어졌을 때, 예측을 해야 하는 문제를 회귀 분석 (regression analysis) 라고 부른다.
회귀 분석에서는 예측 변수가 주어지고 연속적인 변수 (결과) 가 주어지면 변수들의 관계를 찾은 후 결과를 예측해야 한다.
일반적으로 예측 변수는 피처 (features) 로 많이 표현이 되고, 연속적인 변수는 타겟/라벨 (target/label) 로 많이 표현 된다.
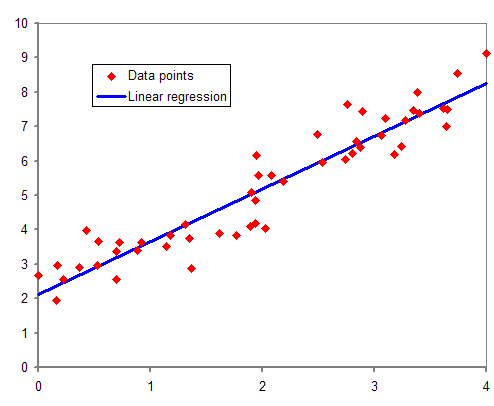
예시로는 영어 공부를 한 시간 (X) 과 그에 대한 영어 시험 점수 (y) 로 볼 수 있다. 각 X와 y를 2차 평면위에 점으로 표현을 한 후 줄을 긋는다면 각 점에 거리가 최소화되는 줄을 긋고 해당 줄의 기울기와 절편을 찾아 새로운 데이터의 예측값을 찾는 것이 목표다.
아래 그림을 보면 이해하는데 도움이 된다.
비지도 학습 (Unsupervised learning)
비지도학습은 지도학습과 다르게 정답이 없는 데이터를 다룬다. 정답이 없으니 데이터의 구조를 파악하고 의미있는 정보를 추출하여 학습하는 방식을 뜻한다.
클러스터링 (Clustering)
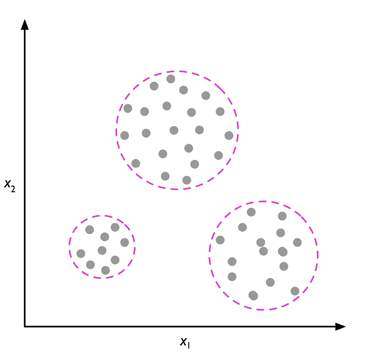
클러스터링은 아무런 사전정보 없이 데이터를 유의미한 소그룹으로 그룹화 시키는 방식을 말한다.
그룹화된 데이터들은 유사도를 공유하지만, 그것보다도 다른 그룹들과 더 비슷하지 않음을 뜻하기에 비지도 분류기 (unsupervised classification)이라고 불리기도 한다.
예를 들어 마케팅 부서에서 고객들의 관심사에 따라 분류를 하여 특별한 프로모션을 제공하는 것처럼 클러스터링을 사용할 수 있다.
클러스터링 예시:
차원 축소 (Dimensionality reduction)
많은 실생활 데이터는 고차원으로 수집이 되고 그대로 사용하기에는 메모리 및 컴퓨팅 자원 낭비와 알고리즘 성능 저하를 야기한다.
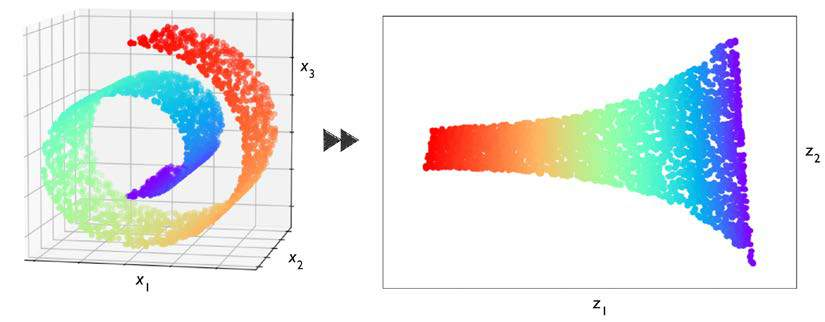
이를 해결하기 위한 방안으로 피쳐 전처리 (feature preprocessing)시에 고차원 데이터를 저차원 데이터로 축소 시키는 비지도 차원 축소를 통해 데이터에 노이즈를 제거한다.
또한 시각화 할때도 유용히 사용이 가능한 방법이기도 하다. 아래 그림은 3차원 데이터를 2차원으로 축소시켜 시각화 하는 것을 보여준다.
강화학습 (Reinforced learning)
머신러닝의 한가지 타입으로 시스템/에이전트 (agent)가 상황에 따라 어떤 행동을 취할 시, 행동에 맞는 보상을 줌으로써 학습을 통해 더 나은 행동을 취하는 방식을 뜻한다.
다만 지도학습과는 달리 정답을 제공하지 않기에 피드백을 통해 행동을 개선한다.
예시로 체스를 두는 머신러닝 프로그램을 생각해볼 수 있다.
여기서 놓여진 체스말의 위치 및 상황에 따라 게임을 이기기 위해 계산을 하고 실패와 반복을 통해 배워나가는 학습 방식을 보면 된다.
아래 그림은 강화학습의 흐름을 보여준다.
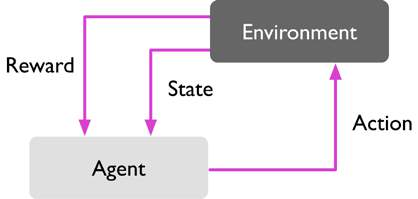
대표적으로 많이 사용되는 강화학습 알고리즘은 다음과 같다:
Monte Carlo methods
Q-Learning
Policy Gradient methods

댓글